def_get_batch_result(self, metaname):
batch_dict = {}
for b in self.client.batches.list(limit=100).data:
batch_name = b.metadata.get('batch_name', '')
if metaname != batch_name:
continue
batch_dict[b.id] = b.status
whileTrue:
for batch_id in batch_dict.keys():
b = self.client.batches.retrieve(batch_id)
batch_dict[batch_id] = b.status
ifall(v in ('completed', 'failed') for v in batch_dict.values()):
break
time.sleep(10)
result = []
for batch_id in batch_dict.keys():
b = self.client.batches.retrieve(batch_id)
if b.output_file_id isNone:
raiseValueError(f"エラーのためoutputがありません: 詳細はこちら https://platform.openai.com/batches/{batch_id}")
content = self.client.files.content(b.output_file_id).read().decode('utf-8')
for c in content.split('\n'):
if c == "":
continue
cd = json.loads(c)
result.append(cd)
return result
before: オンプレミス IT資産管理ツール
after: Microsoft Intune / Jamf Pro
Mac の標準スペックは 2024/12 時点でM4 Max(RAM 64GB)、社内に Intel Mac は0
以前は Windows と Mac それぞれの OS 向けの資産管理ツールをオンプレミスのサーバー上に載せており、オフィスのサーバールームで元気に稼働していました。
Windows Server の EOL のタイミングなどもあり、フルクラウド型のモバイルデバイス管理(MDM:Mobile Device Management)への移行を検討し、Windows は Microsoft Intune、Mac は Jamf Pro を選定しました。
MDM 導入前は入社準備でデスクに PC、iPhone、iPad を数十台並べてひたすらセットアップする光景が風物詩でしたが、Windows は Windows Autopilot、Mac、iPhone、iPad は Apple Business Manager と連携した Automated Device Enrollment によりゼロタッチデプロイが可能になり、キッティングにかかる工数を大幅に削減できました。
iPhone / iPad については当時すでに別の MDM が導入されていたのですが、後にリプレイスを行い、現在は Mac と合わせて全て Jamf Pro で統合管理されています。これらの製品は MDM として広く知られているものなので、詳細な説明は割愛します。
当時の一休はエンジニアも含めて Windows の割合が非常に高く、 Windows / Mac 比率 8:2 という状態からの Jamf Pro 導入でした。
マイノリティである Mac は冷遇されがちでほぼ野良管理、自己責任での利用という状態から、Jamf Pro により適切に管理・統制された状態まで進めることができました。
Windows 混在環境における Jamf Pro 導入については、 Jamf Connect も含め導入事例、プレスリリースで広く紹介していただいています。
サーバーの保守運用コストがかかるだけではなく、デバイスへの負荷が大きい、最新 OS への対応が遅い、パターンマッチングでの検知・検疫はできる一方で、侵入後のリアルタイム検知ができないなどの課題もあり、EDR(Endpoint Detection and Response)型のセキュリティ製品へのリプレイスを検討している中で、Microsoft Defneder for Endpoint(以下、 MDE)を導入しました。
Mac については Jamf Protect という製品もありますが、Windows / Mac / iOS / iPadOS などマルチ OS に対応している点からも、Apple デバイスも MDE で運用しています。
同時期に SIEM(Security Information and Event Management)として Microsoft Sentinel を導入しており、MDE や Microsoft Defender for Identity などで検知したログは Microsoft Sentinel に集約され、インシデントは Slack に通知され、リアルタイムに検知・分析・対応ができる運用をしています。
こちらでコスト可視化や Microsoft Entra ID の SCIM(System for Cross-domain Identity Management)によるプロビジョニングに対応していない SaaS の棚卸しを実施していきます。まだ導入して日が浅いため、運用設計のノウハウが溜まってきたらどこかでアウトプットできればと思います。
ヘルプデスクの改善
before: Google フォーム
after: Jira Service Management
6年前のエントリでは Google フォームでヘルプデスク対応を行っていると書きましたが、その後、Halp という製品を導入し、Halp が Atlassian に買収されたことで、Jira Service Management(以下、JSM)に統合されました。
Slack のプレミアムワークフローが無償化したことから移行も検討していますが、現時点ではまだ機能に不足を感じており、JSM での運用を続ける予定です。
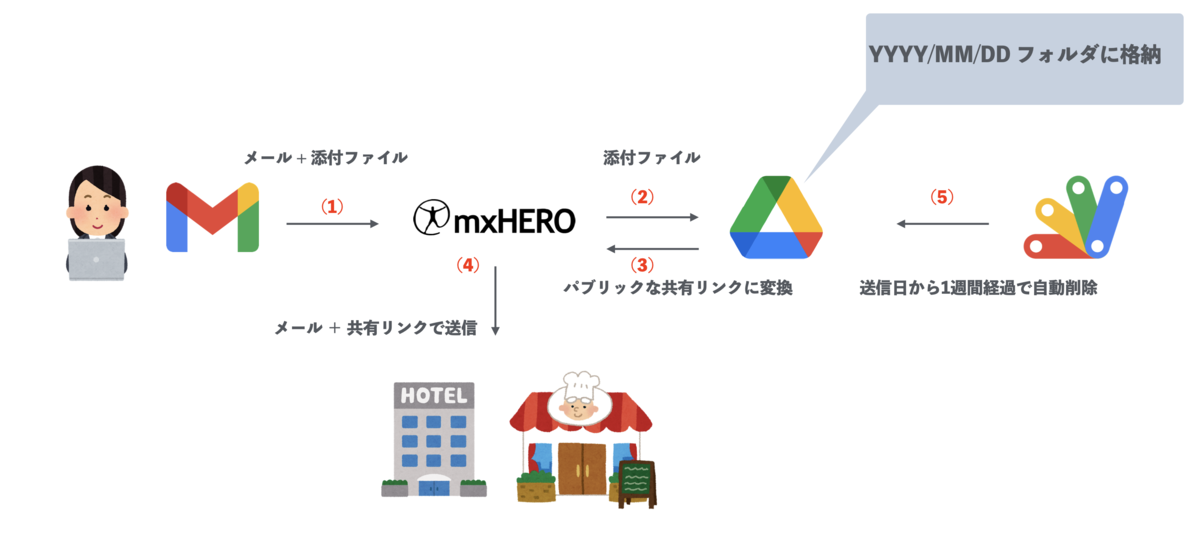
メールの添付ファイルを自動的にファイルストレージの安全な共有リンクに変換して送信することから、誤送信をしてしまった場合もファイルを消したり、アクセス権限を解除したりすることで、情報漏えいを防止することができます。これにより PPAP を代替できると考えました。
一休ではファイルストレージとして Google ドライブを利用しているため、mxHERO と Google ドライブを組み合わせて導入することを検討しました。
Google ドライブは Box と比較すると制限が多い
しかし、Google ドライブは Google アカウントが前提となっていることが多く、Box と比較すると制限事項が多くありました。特に共有リンクに有効期限が付与できないと、共有が不要になったファイルも、設定変更を忘れると URL を知っていれば永久的にアクセスできてしまう可能性があり、解決する必要のある課題でした。
Box の導入も検討しましたが、既存のファイル共有ツールを比較するとランニングコストが大幅に上がってしまうことから断念しました。
本記事では TypeScript の Discriminated Union による代数的データ型の模倣についてまずその基本を確認し、その後 Haskell の代数的データ型の文法をみていきます。後者をみて先のメンタルモデルを獲得したのちに前者を改めて眺めてみることにより、新たな視点で TypeScript の機能を捉えることを目指します。
TypeScript の Discriminated Union (判別可能な Union 型)
TypeScript の Discriminated Union (判別可能な Union 型) を使うと、他のプログラミング言語でいうところの代数的データ型のユースケースを模倣することができます。Discriminated Union はディスクリミネーター (もしくはタグ) と呼ばれる文字列リテラルにより Union で合併した型に含まれる型を判別できるところから「タグつき Union 型」と呼ばれることもあります。
Discriminated Union をうまく使うと、アプリケーション開発において「存在しない状態」ができることを回避することが出来ます。存在する状態のみを型で宣言することで「存在しない状態ができていないこと」を型チェックにより保証することができます。書籍 Domain Modeling Made Functional などでも語られている非常に有用な実装パターンであり、一休が扱う予約などの業務システム開発でも頻繁に利用しています。
仮に Discriminated Union を使わず、ゲストユーザーを「ID が null」で表現したとすると以下のように定義することになります。
type User ={id: number|nullname?: stringemail?: string}
この場合、たとえば ID が null にも関わらず name や email が null でない、という「ありえない状態」を表現できてしまいます。
これは Record 型が AND (積) に基づいたデータ構造の宣言であり、3 つのプロパティがそれぞれ「ある・なし」の 2パターンを取り、その積で合計 8 パターンの状態を取れてしまうことに起因しています。8パターンの状態の中には、実際にはあり得ない状態が含まれます。「ある・ なし」の分岐は ID に関してだけでよいのに、ほかの 2 つのプロパティまでそれに巻き込まれてしまった結果です。
Union 型は OR (和) に基づく合併なので「ID、名前、メールアドレスがある」 Member に、「プロパティがない」 Guest の状態を「足している」だけ。状態の積は取りません。よって合併しても状態が必要以上に増えません。
Making illegal states unrepresentable (ありえない状態を表現しない) というのはこういうことです。
-- データ型の宣言data Tree a = Leaf a | Node (Tree a) (Tree a)
-- 木を根から走査。パターンマッチと再帰で辿っていく
read :: Int -> Tree a -> a
read _ (Leaf x) = x
read i (Node left right)
| i < size left = read i left
| otherwise = read (i - size left) right
write :: Int -> a -> Tree a -> Tree a
write _ v (Leaf _) = Leaf v
write i v (Node left right)
| i < size left = Node (write i v left) right
| otherwise = Node left (write (i - size left) v right)
size :: Tree a -> Int
size (Leaf _) =1
size (Node left right) = size left + size right
fromList :: [a] -> Tree a
fromList [] = error "Cannot build tree from empty list"
fromList [x] = Leaf x
fromList xs =let mid = length xs `div`2in Node (fromList (take mid xs)) (fromList (drop mid xs))
main :: IO ()
main =dolet arr = fromList [1..8:: Int]
print $ read 3 arr -- 3let arr' = write 342 arr
print $ read 3 arr' -- 42
print $ read 3 arr -- 3
重要なポイントとしては、コメントに書いたとおり (1) 完全二分木の木構造を data キーワードのみで宣言していること、(2) 木の中から目的のノードを探すにあたりパターンマッチで分解しながら走査していること、の 2 点が挙げられます。
データ型の宣言を改めてみてみましょう。
data Tree a = Leaf a | Node (Tree a) (Tree a)
Tree 型が再帰的に宣言されているのがわかります。再帰データ型が宣言できるため、木のようなデータ構造を代数的データ型により構築することができます。
同様にリスト構造の List 型を自前で実装してみましょう。リストの走査として先頭に要素を追加する cons 関数と、リストの値それぞれを写像する mapList 関数も実装してみます。
data List a = Empty | Cons a (List a) deriving (Show)
empty :: List a
empty = Empty
cons :: a -> List a -> List a
cons = Cons
mapList :: (a -> b) -> List a -> List b
mapList _ Empty = Empty
mapList f (Cons x xs) = Cons (f x) (mapList f xs)
-- テスト出力
main :: IO ()
main =dolet xs = cons 1 (cons 2 (cons 3 empty))
print (mapList (*2) xs) -- Cons 2 (Cons 4 (Cons 6 Empty))
目論見どおり、TypeScript の Discriminated Union に対する印象をアップデートすることができたでしょうか? できていることを願います 😀
実務で Discriminated Union を用いて再帰データ構造を宣言する、という機会はあまりないとは思いますが、それがただの Union で併合された型を判別できるものと小さく捉えるのではなく、本稿でみた通りデータ型の構築と分解の観点で捉えておくと視点が拡がるでしょうし、より広範囲に適用していってよいものだという確証が得られるのではないかと思います。