この記事は 一休.com Advent Calendar 2024 の3日目の記事です。
昨今は我々一休のような予約システム開発においても、関数型プログラミング由来のプラクティスを取り入れる機会が増えています。
例えば、値はイミュータブルである方が扱いやすい、関数は副作用のない純粋関数にする方がテスタビリティなども含め何かと都合がよい、そういう場面では積極的に不変な値を使い、関数が冪等になるよう意識的に実装します。ドメインロジックを純粋関数として記述できると、堅牢で責務分離もしやすく、テストやデバッグもしやすいシステムになっていきます。
ところで「関数型プログラミングとはなんぞや」というのに明確な定義はないそうです。ですが突き詰めていくと、計算をなるべく「文」ではなく「式」で宣言することが一つの目標だということに気がつきます。
文と式の違いは何でしょうか?
for 文、代入文、if 文などの文は、基本的には値を返しません。値を返さないということは、文は直接結果を受け取るものではなく、命令になっていると言えます。文は計算機への命令です。
一方の式は、必ず返値を伴いますから、その主な目的は返値を得る、つまり式を評価して計算の結果を得ることだと考えることができます。
customer.archive()
と、文によって暗黙的に customer オブジェクトの内部状態を変更するのではなく
const archivedCustomer = archiveCustomer(customer)
と、引数で与えられた customer オブジェクトを直接変更することなしに、アーカイブ状態に変更されたコピーとしての archivedCustomer オブジェクトを返値として返す、これが式です。この関数は純粋関数として実装し、customer オブジェクトは不変、つまりイミュータブルなものとして扱うと良いでしょう。
式によるイミュータブルなオブジェクトの更新は TypeScript なら
export const archiveCustomer = (customer: Customer): Customer => ({ ...customer, archived: true })
と、スプレッド構文を使うことで customer オブジェクトのコピーを作りつつ、変更したいプロパティを新たな値に設定したものを返すように実装します。
このように、引数で与えたオブジェクトは直接変更せず、状態を変更した別のオブジェクトを返すような関数の連なりによって計算を定義していくのが関数型プログラミングです。
このあたりの考え方については、過去の発表スライドがありますので参考にしてください。
実際、我々の一部プロダクトのバックエンドでは TypeScript による関数型スタイルでの開発を実践しています。以下はプロダクトのコードの一例で、Customer オブジェクトに新しいメールアドレスの値を追加するための addEmail 関数です。先の実装に同じく、スプレッド構文を使って元のオブジェクトを破壊せずに、メールアドレスが追加されたオブジェクトを返します。
const addEmail = (address: EmailAddress) => (customer: Customer): Customer => { const newAddress: CustomerEmail = { id: generateCustomerEmailId(), address, } return { ...customer, emails: [...customer.emails, newAddress], } }
ドメインオブジェクトの状態遷移はすべて、この式による状態遷移のモデルで実装しています。
永続データプログラミング
さて、本記事のテーマは「永続データ」です。永続データとは何でしょうか?
式を意識的に使い、かつ値をイミュータブルに扱うことを基本としてやっていくと、何気なく書いたプログラムの中に特徴的な様子が現れることになります。
以下、リスト操作のプログラムを見てみましょう。リストの先頭や末尾に値を追加したり、適当な値を削除する TypeScript のプログラムです。リストをイミュータブルに扱うべく、値の追加や削除などデータ構造の変更にはスプレッド構文を使い、非破壊的にそれを行うようにします。
// as1: 元のリスト const as1 = [1, 2, 3, 4, 5]; // as2: 新しいリスト (先頭に 100 を追加) const as2 = [100, ...as1]; // as3: 新しいリスト (末尾に 500 を追加) const as3 = [...as2, 500]; // as4: 新しいリスト (値 3 を削除) const as4 = as3.filter(x => x !== 3); console.log("as1:", as1); // [1, 2, 3, 4, 5] console.log("as2:", as2); // [100, 1, 2, 3, 4, 5] console.log("as3:", as3); // [100, 1, 2, 3, 4, 5, 500] console.log("as4:", as4); // [100, 1, 2, 4, 5, 500]
更新をしても元のリストは不変なので、as1 を参照しても更新済みの結果は得られません。リスト操作の返り値を as2 as3 as4 とその都度変数にキャプチャし、そのキャプチャした変数に対して次のリスト操作を行います。こうしてデータ構造は不変でありつつも一連の、連続したリスト操作を表現します。
データ構造を不変にした結果、リストが更新される過程の状態すべてが残りました。リストを何度か更新したにも関わらず、変更前の状態を参照することができています。as1 を参照すれば初期状態を、as2 や as3 で途中の状態を参照することができます。このように値の変更後もそれ以前の状態が残るさまを「永続データ」と呼びます。そして永続データを用いたプログラミングを「永続データプログラミング」と呼びます。
値をイミュータブルに扱うと必然的にそれは永続データになるので、永続データプログラミングはそれ自体、何か特別なテクニックというわけではありません。一方で、値が永続データであることをはっきりさせたい文脈上では「永続データプログラミング」という言葉でプログラミングスタイルを表現すると、その意図が明確になることも多いでしょう。
以下の山本和彦さんの記事では、関数型プログラミングすなわち「永続データプログラミング」であり、永続データを駆使して問題を解くことこそが関数型プログラミングだ、と述べられています。
筆者の関数プログラミングの定義、すなわちこの特集での定義は、「永続データプログラミング」です。永続データとは、破壊できないデータ、つまり再代入できないデータのことです。そして、永続データを駆使して問題を解くのが永続データプログラミングです。
また関数型言語とは、永続データプログラミングを奨励し支援している言語のことです。関数型言語では、再代入の機能がないか、再代入の使用は限定されています。筆者の定義はかなり厳しいほうだと言えます。
命令型プログラミングにおいては変更にあたり値を直接破壊的に変更します。変更前のデータ構造の状態を参照することはできません。リストの破壊的変更は、基本的に (式ではなく) 文によって行われるでしょう。文を主体としたプログラミング··· 命令型プログラミングでは、永続ではないデータ、つまり短命データを基本にしていると言えます。一方、式によってプログラムを構成する関数型プログラミングでは、関数の冪等性を確保すべくイミュータブルに値を扱うことになるので、永続データが基本になります。
イミュータブルな値によるプログラミングをする際、そこにある値は不変であるだけでなく、同時に永続データなのだということを認識できると、プログラミングスタイルに対するよりよいメンタルモデルが構築できると思います。
Haskell と永続データプログラミング
やや唐突ですが、イミュータブルといえば純粋関数型言語の Haskell です。先の TypeScript によるリスト操作のプログラムを、Haskell で実装してみます。
main :: IO () main = do let as1 = [1, 2, 3, 4, 5] as2 = 100 : as1 as3 = as2 ++ [500] as4 = delete 3 as3 print as1 -- [1,2,3,4,5] print as2 -- [100,1,2,3,4,5] print as3 -- [100,1,2,3,4,5,500] print as4 -- [100,1,2,4,5,500]
Haskell はリストはもちろん、基本的に値がそもそもがイミュータブルです。リスト操作の API はすべて非破壊的になるよう実装されているので、変更にあたり TypeScript のようにスプレッド構文でデータを明示的にコピーしたりする必要はありません。裏を返せば、変更は永続データ的に表現せざるを得ず、式によってプログラムを構成することが必須となります。結果、Haskell による実装は自然と永続データプログラミングになります。
関数型プログラミングすなわち永続データプログラミングだ、というのは、この必然性から来ています。
永続データの特性を利用した問題解決
永続データプログラミングは不変な値を使うことですから、それを実践することで記事冒頭で挙げたようなプログラムの堅牢性など様々なメリットを享受できるわけですが、「変更前の過去の状態を参照できる」という、値が不変であるというよりは、まさに「永続」データの特性が部分が活きるケースがあります。
わかりやすい題材として、競技プログラミングの問題を例に挙げます。
問題文を読むのが面倒な方のために、これがどんな問題か簡単に解説します。入力の指示に従ってリストを更新しつつ、任意のタイミングでそのリストの現在の状態を保存する。また任意のタイミングで復元できるようするという、データ構造の保存と復元を題材にした問題です。
ADD 3 SAVE 1 ADD 4 SAVE 2 LOAD 1 DELETE DELETE LOAD 2 SAVE 1 LOAD 3 LOAD 1
こういうクエリが入力として与えられる。
- 空のリストが最初にある
- クエリを上から順番に解釈して、
ADD 3のときはリスト末尾にを追加する
DELETEなら末尾の値を削除SAVE 1のときは、今使っているリストを ID 番号の領域に保存、
LOAD 1なら ID 番号- クエリのたび、その時点でのリストの末尾の要素を出力する
という問題になっています。
この問題を永続データなしで解こうとすると、リストを更新しても以前の状況に戻れるような木のデータ構造を自分で構築する必要がありなかなか面倒です。一方、永続データを前提にすると、何の苦労もなく解けてしまいます。
以下は Haskell で実装した例です。やっていることは、クエリの内容に合わせてリストに値を追加・削除、保存と復元のときは辞書 (IntMap) に、その時点のリストを格納しているだけです。問題文の通りにシミュレーションしているだけ、とも言えます。
main :: IO () main = do q <- readLn @Int qs <- map words <$> replicateM q getLine let qs' = [if null args then (command, -1) else (command, stringToInt (head args)) | command : args <- qs] let res = scanl' f ([], IM.empty) qs' where f (xs, s) query = case query of ("ADD", x) -> (x : xs, s) -- リストに値を追加 ("DELETE", _) -> (drop1 xs, s) -- リストから値を削除 ("SAVE", y) -> (xs, IM.insert y xs s) -- 辞書にこの時点のリストを保存 ("LOAD", z) -> (IM.findWithDefault [] z s, s) -- 辞書から保存したリストを復元 _ -> error "!?" printList [headDef (-1) xs | (xs, _) <- tail res] -- 各クエリのタイミングでのリストの先頭要素を得て、出力
Haskell のリストは永続データですから、値を変更しても変更以前の値が残ります。その値が暗黙的に他で書き換えられる事はありません。よって素直にリストを辞書に保存しておけばよいのです。一方、命令型プログラミングにおいてリストがミュータブルな場合は、ある時点の参照を辞書に保存したとしても、どこかで書き換えが発生すると、辞書に保存された参照の先のデータが書き換わるためうまくいきません。
永続データ構造
さて、ここからが本題です。TypeScript でリストを永続データとして扱うにあたり、スプレッド構文によるコピーを使いました。
// as2: 新しいリスト (先頭に 100 を追加) const as2 = [100, ...as1]; // as3: 新しいリスト (末尾に 500 を追加) const as3 = [...as2, 500];
すでにお気づきの方も多いと思いますが、値の更新にあたり、リスト全体のコピーが走ってしまっています。一つ値を追加、削除、更新するだけでもリストの要素 件に対し
件のコピーが走る。つまり
の計算量が必要になってしまいます。永続データプログラミングは良いものですが、ナイーブに実装するとデータコピーによる計算量の増大を招きがちです。
Haskell など、イミュータブルが前提のプログラミング言語はこの問題をどうしているのでしょうか?
結論、データ構造全体をコピーするのではなく「変更されるノードとそのノードへ直接的・間接的に参照を持つノードだけをコピーする」ことによって計算量を抑え、不変でありながらも効率的なデータ更新が可能になるようにリストその他のデータ構造が実装されています。つまり同じ「リスト」でも、命令型プログラミングのそれと、不変なデータ構造のそれは実装自体が異なるのです。抽象は同じ「リスト」でも具体が違うと言えるでしょう。
変更あったところだけをコピーし、それ以外は元の値と共有を行うこのデータ構造の実装手法は Structural Sharing と呼ばれることもあります。Structural Sharing により不変でありながら効率的に更新が可能な永続データのデータ構造を「永続データ構造」と呼びます。
永続データ構造については、以下の書籍にその実装方法含め詳しく記載されています。
もとい、例えば Haskell のリストは先頭の値を操作する場合は です。先頭要素だけがコピーされていて、それ以降の要素が更新前後の二つのリストで共有されるからです。
同じく、先の実装でも利用した Data.IntMap という辞書、こちらも永続データ構造ですが、内部的にはパトリシア木で実装されていて、値の挿入やキーの探索は、整数のビット長程度の計算量 ··· をデータサイズ、
をビット長としたとき
に収まります。
Haskell で利用する標準的なデータ構造 ··· List、Map、Set、Sequence、Heap は、すべてイミュータブルでありながら、値の探索や変更が や
程度の計算量で行える永続データ構造になっています。(なお、誤解の無いよう補足すると、ミュータブルなデータ構造もあります。ミュータブルなデータ構造は手続き的プログラミングで変更することになります)
永続データ構造を利用することによって、永続データプログラミング時にもパフォーマンスをそれほど犠牲にせず、大量のデータを扱うことが可能になります。裏を返せば、永続データプログラミングをより広範囲に実践していくには、永続データ構造が必要不可欠であるとも言えます。関数型プログラミングは値が不変であることをよしとしますが、そのためには永続データ構造が必要かつ重要なパーツなのです。
TypeScript その他のプログラミング言語で永続データプログラミングを実践するとき、純粋関数型言語とは異なり、素の状態では永続データ構造の支援がないということは念頭に置いておくべきでしょう。
TypeScript や Python で永続データ構造を利用するには?
TypeScript の Array、Map、Set などの標準的なデータ構造はすべて命令型データ構造、つまりミュータブルです。命令型のプログラミング言語においては、どの言語も同様でしょう。一方、プログラミング言語によっては List、Map、Set などの永続データ構造バージョンを提供するサードパーティライブラリがあります。
- Immutable.js (JavaScript / TypeScript)
- pyrsistent · PyPI (Python)
これらのライブラリを導入することで、TypeScript や Python で永続データ構造を利用することができます。しかし、実際のところこれらの永続データ構造の実装が、広く普及しているようには思えません。
永続データ構造は業務システム開発にも必須か?
結論からいうと、命令型のプログラミング言語で業務システム開発をする場合には、必須ではないでしょう。
永続データプログラミング自体は良い作法ですが、業務システムにおいては、大量データのナイーブなコピーが走るような実装をする場面が少ないから、というのが理由だと思います。
Haskell のような関数型言語を使っているのであれば、永続データ構造は標準的に提供されていて、そもそも必須かどうかすら気にする必要がありません。永続データ構造のメカニズムを全く知らなくても、自然にそれを使ったプログラムを書くように導かれます。
命令型言語を使いつつも、永続データプログラミングを実践するケースではどうでしょうか? 速度が必要な多くの場面では、いったん永続データを諦め、単に命令型データ構造を利用すれば事足りるので、わざわざ永続データ構造を持ち出す必要はないでしょう。ドメインオブジェクトの変更をイミュータブルに表現するためコピーする場合も、せいぜい 10 か 20 程度のプロパティをコピーする程度で、コピー 1回にあたり数万件といったオーダーのコピーが発生するようなことは希でしょう。
よって業務システム開発において Immutable.js や pyrsistent のようなサードパーティライブラリを積極的に使いたい場面は、先に解いた競技プログラミング問題のように、永続データ構造の永続である特性そのものが機能要件として必要になるケースに限られるのではないか? と思います。
Immutable.js の開発が停滞しているのは、フロントエンドで永続データ構造の需要が乏しいからでしょう。このようなデータ構造自体は非常に重要な概念で、多くのプログラミング言語に存在します。我々フロントエンドエンジニアが依存するブラウザの内部でも、効率的なデータ処理のために多用されているはずです。しかし、フロントエンドエンジニアがイミュータブルに求めているのは処理速度ではなく設計の改善です。だからこそ、Immutable.js に代わって Immer が隆盛したのでしょう。
一方、純粋関数型言語で競技プログラミングのような大きなデータを扱うプログラミングを行う場合、永続データ構造は必須ですし、また永続データ構造を利用していることを意識することでよりよい実装が可能になると思っています。個人的にはこの「永続データ構造によって、より良い実装が可能になる」点こそが本質的だと思っています。
先の競技プログラミングの実装を改めてみてみます。
main :: IO () main = do q <- readLn @Int qs <- map words <$> replicateM q getLine let qs' = [if null args then (command, -1) else (command, stringToInt (head args)) | command : args <- qs] let res = scanl' f ([], IM.empty) qs' where f (xs, s) query = case query of ("ADD", x) -> (x : xs, s) -- リストに値を追加 ("DELETE", _) -> (drop1 xs, s) -- リストから値を削除 ("SAVE", y) -> (xs, IM.insert y xs s) -- 辞書にこの時点のリストを保存 ("LOAD", z) -> (IM.findWithDefault [] z s, s) -- 辞書から保存したリストを復元 _ -> error "!?" printList [headDef (-1) xs | (xs, _) <- tail res] -- 各クエリのタイミングでのリストの先頭要素を得て、出力 (※)
このプログラムでは、クエリのたびに、その時点でのリストの値を出力する必要があります。が、上記のプログラムでは (クエリのたびに都度出力を得ているのではなく) クエリを全部処理し終えてから、最終的な出力、つまりプレゼンテーションを組み立てています。(※) の実装です。
データ構造が命令型データ構造の場合、こうはいきません。ある時点のデータ構造の状態はその時点にしか参照できないため、プレゼンテーションをそのタイミングで得る必要があります。
一方、永続データ構造の場合、各々時点のデータ構造の状態を後からでも参照できますし、メモリ上にデータ構造を保持しておいても Structural Sharing によりそれが肥大化することもありません。このプログラムのように、中核になる計算 ··· つまりドメインロジックをすべて処理し終えてから、改めてプレゼンテーションに変換することが可能です。プレゼンテーション・ドメイン分離の観点において、永続データ構造が重要な役割を果たしています。この考え方は、実装スタイルに大きな影響を与えます。
この点に関する詳細は、競技プログラミング文脈を絡めて話す必要もあり長くなりそうなので改めて別の記事にしようと思います。
さて、業務システム開発には必須とは言えないと私見は述べましたが、命令型プログラミング言語でも値を不変に扱うとき、このナイーブなコピーが走る問題を意識できているかどうかは重要でしょう。多くの関数型言語においてはこの課題を永続データ構造によって解消しているということは、知っておいて損はありません。
永続データ構造の実装例
「永続データ構造」というと字面から何かすごそうなものを思い浮かべるかもしれませんが、その実装方法を知っておくともう少し身近なものに感じられると思います。永続データ構造の中でも比較的実装が簡単な、永続スタックと永続配列の実装を紹介して終わりにしたいと思います。実装の詳細については解説しませんが、雰囲気だけみてもらって「何か特別なことをしなくても普通に実装できるんだな」という雰囲気を掴んでもらえたらと思います。
永続スタック
Haskell で実装した永続スタックの一例です。再帰データ型でリストのようなデータ構造を宣言し、API として head tail (++) など基本的な関数を実装します。
代数的データ型でリンクリスト構造を宣言し、先頭要素への参照を返すように実装します。先頭要素を参照したいとき (head) は、先頭要素への参照からそれを取り出し値を得るだけ。先頭以外の要素を得る、つまり分解したいとき (tail) は次の要素への参照を返す。これだけで永続スタックが実装できます。
二つのスタックを結合する ((++)) ときはどうしても かかってしまいますが、その際も双方のリストをコピーするのではなく古いリストの一方だけをコピーし、のこりの一つは新しいリストで共有されるように実装しています。
import Prelude hiding ((++)) data Stack a = Nil | Cons a (Stack a) deriving (Show, Eq) empty :: Stack a empty = Nil isEmpty :: Stack a -> Bool isEmpty Nil = True isEmpty _ = False cons :: a -> Stack a -> Stack a cons = Cons head :: Stack a -> a head Nil = error "EMPTY" head (Cons x _) = x tail :: Stack a -> Stack a tail Nil = error "EMPTY" tail (Cons _ xs) = xs (++) :: Stack a -> Stack a -> Stack a Nil ++ ys = ys Cons x xs ++ ys = Cons x (xs ++ ys) main :: IO () main = do let s0 :: Stack Int s0 = empty s1 = cons (1 :: Int) s0 s2 = cons (2 :: Int) s1 s3 = cons (3 :: Int) s1 s4 = s1 ++ s3 print s0 print s1 print s2 print s3 print s4
出力結果は以下です。
Nil Cons_1_Nil Cons_2_(Cons_1_Nil) Cons_3_(Cons_1_Nil) Cons_1_(Cons_3_(Cons_1_Nil))
永続配列
永続配列は、配列といっても命令型の配列のように連続した領域を索引で参照できるようにするモデルではなく、完全二分木で表現します。
値は葉に持たせて、インデックスによる参照時には根から二分木を辿って目的の葉を特定します。そのため、参照時の計算量は ではなく
となります。
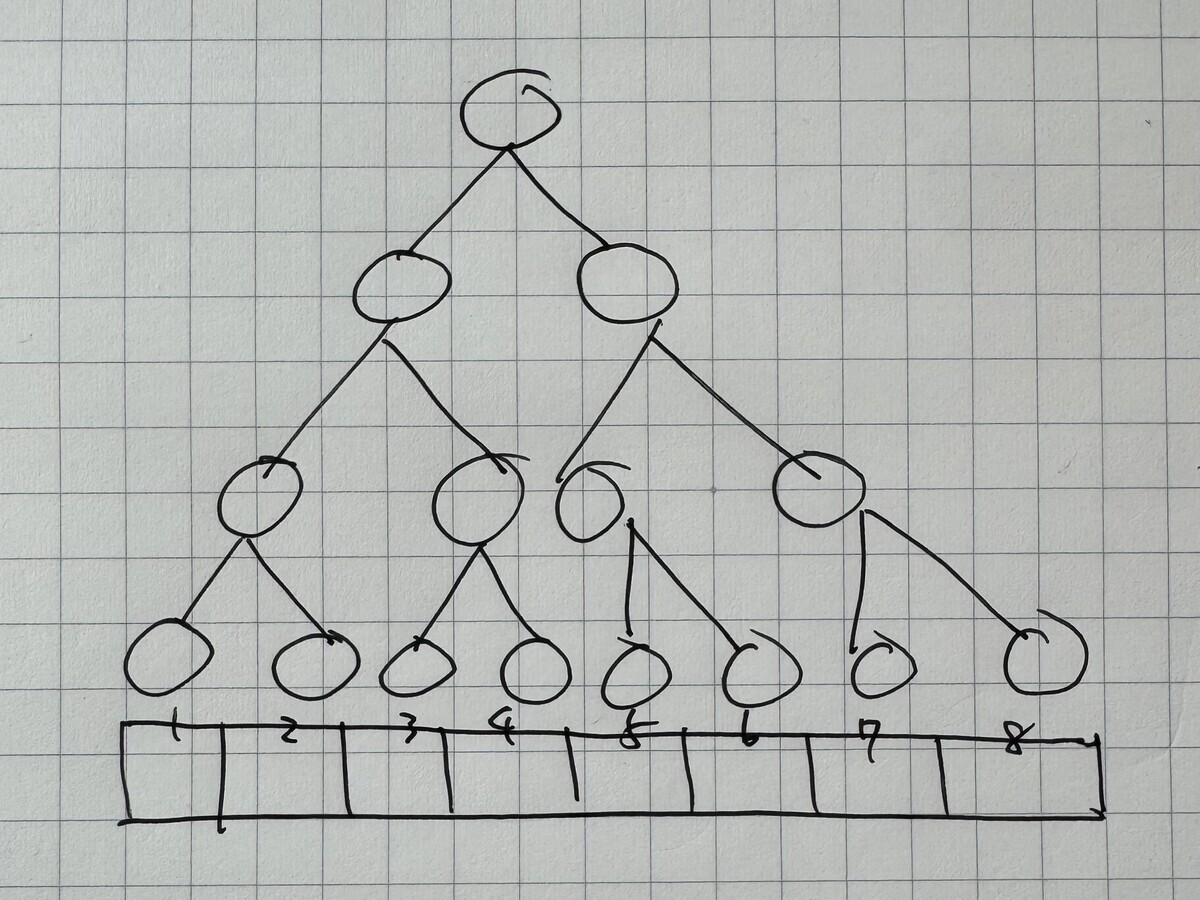
更新時には「変更されるノードとそのノードへ直接的・間接的に参照を持つノードだけをコピーする」という考えに従い、根から更新対象の葉までを辿る経路上のノードをコピーする経路コピーという手法を使います。経路をコピーするといっても、木の高さ程度ですから更新も結局 になります。
経路コピーについては Path Copying による永続データ構造 - Speaker Deck のスライドがわかりやすいと思います。
{-# LANGUAGE DeriveFunctor #-} import Prelude hiding (read) data Tree a = Leaf a | Node (Tree a) (Tree a) deriving (Show, Functor) fromList :: [a] -> Tree a fromList [] = error "Cannot build tree from empty list" fromList [x] = Leaf x fromList xs = let mid = length xs `div` 2 in Node (fromList (take mid xs)) (fromList (drop mid xs)) read :: Int -> Tree a -> a read _ (Leaf x) = x read i (Node left right) | i < size left = read i left | otherwise = read (i - size left) right write :: Int -> a -> Tree a -> Tree a write _ v (Leaf _) = Leaf v write i v (Node left right) | i < size left = Node (write i v left) right | otherwise = Node left (write (i - size left) v right) size :: Tree a -> Int size (Leaf _) = 1 size (Node left right) = size left + size right main :: IO () main = do let arr = fromList [1 .. 8 :: Int] print arr print $ read 3 arr let arr' = write 3 42 arr print $ read 3 arr' print $ read 3 arr
永続スタック、永続配列の実装を簡単ですが紹介しました。
何か特殊な技法を使うというものではなくスタック、配列などの抽象が要求する操作を考え、その抽象に適した具体的で効率的なデータ構造を用意する、というのが永続データ構造の実装です。
まとめ
永続データプログラミングと永続データ構造について解説しました。
- 不変な値を使い、式でプログラムを宣言すると永続データプログラミングになる
- 永続データプログラミングでは、変更前の値を破壊しない。変更後も変更前の値を参照できるという特徴を持つ
- 関数型プログラミングすなわち永続データプログラミングである、とも考えられる
- 永続データプログラミングにおけるデータコピーを最小限に留め効率的な変更を可能にする不変データ構造が「永続データ構造」
- 業務システム開発において、永続データ構造は必須とは言えない。パフォーマンスが必要な場面で、永続データ構造を持ち出す以外の解決方法がある
- 大量データを扱うことが基本で、かつ値を不変に扱いたいなら永続データ構造は必須
- 一般のシステム開発においても機能要件として「永続」データが必要になるなら、Immutable.js とかを利用しても良いかも
- 関数型プログラミングが、不変でありながらも値の変更をどのように実現しているかは永続データ構造に着目するとよく理解できる
というお話でした。
途中少し触れた、永続データ構造を前提にした計算の分離については別途あらためて記事にしたいと思います。
追記
以下に記事にしました。