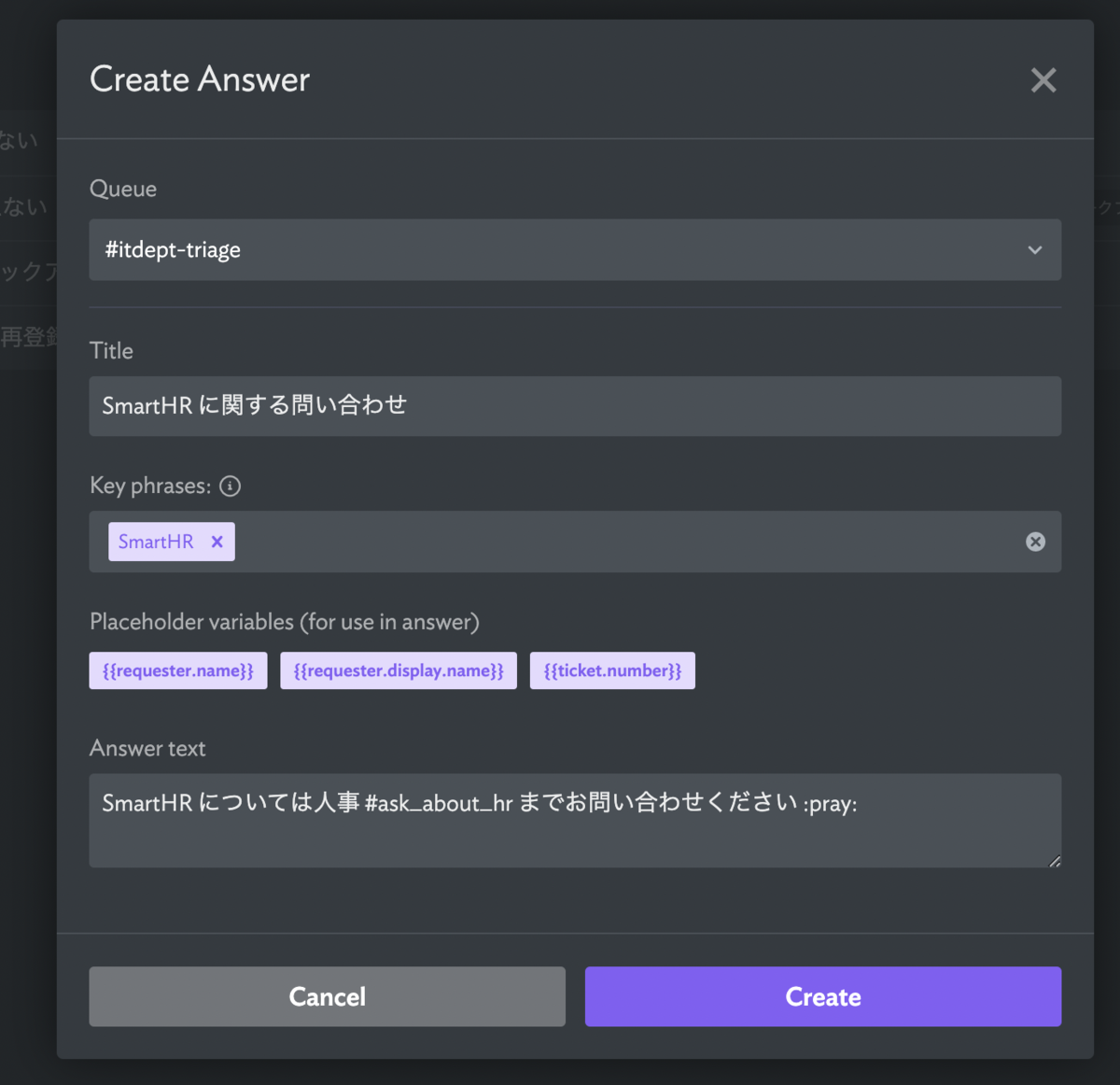
こんにちは。宿泊事業本部 プロダクト開発部 UI/UXチーム の 岡崎です。
今回は、「個人的」に「プロダクト開発で大事にしていること」をテーマに話を進めます。
概要
大事にしている事は下記3つあります。
それぞれにフォーカスして話を進めます。
- 1.「ユーザーファースト」
- 2.「チームワーク」
- 3.「アーキテクチャ」
なぜ大事にしているのか?
「ユーザーファースト」
- ユーザーに価値を届けられないプロダクトは「無意味」である為
「チームワーク」
- 良いプロダクトを生み出す為に「自分が不得意な分野の知識を借りる」事が必要不可欠である為
「アーキテクチャ」
- 速いサイクルでプロダクトの改善をする為に必要不可欠である為
「ユーザーファースト」を大事にする
Q.「ユーザファースト」を大事にするとは?
A. ユーザが使い心地の良い機能かを考える事
私の場合は、これをまず最初に考えてプロダクト開発をします。
具体的には、以下のテクニックを利用しています。
- 1.軽く機能を作成してフィードバックを得る
- 2.最終的なUI/UXの決定を長けている人に任せる
- 3.CVRを確認する
軽く機能を作成してフィードバックを得る
エンジニアにありがちなのが、手段と目的の逆転現象です。
例えば、モダンなUIフレームワークを利用して、イケているデザインを作ろう。
という風に考えると破綻します。
手段を考えるよりも先に「どうしたらユーザが困っている事を解決できるか?」を考えて
プログラミングに臨むことが大事だと思います。
そのためにも、HTML/CSS/JavaScript だけで静的なコンポーネントを作ってみて「そもそも使い勝手良いんだっけ?」
と社内のメンバーにフィードバックを得るなどの行為は大事になってくると思います。
最終的なUI/UXの決定を長けている人に任せる
「デザインスプリント」「アジャイル開発」などのフレームワークでは、
「皆で議論して」「付箋」「ホワイトボード」... などのワードが目立つと思います。
「皆で議論する」... 事自体は、問題ないですが、最終的に「誰がUI/UXを決めるか?」は大事になります。
「民主主義」で決めたり「エンジニア」が決めてしまう場合は、「それぞれの欲しいデザイン」になりがちです。
UI/UXに関する内容の決定権は、「ユーザの行動分析が得意な人」や「デザイナー」に責任をもってもらう事が重要だと思います。
CVRを確認する
CVRを確認する理由は、「CVRが上昇≒ユーザが使いやすいと思っている」という方程式が成り立ちやすいからです。 そのためにも、以下は大事になってくると思います。
- A/Bテストの仕組みを整えておくこと
- カナリーリリースの仕組みを整えておくこと
- データレイクにデータを送信する仕組みを整えておくこと
- 分析基盤を整えておくこと
「チームワーク」を大事にする
Q.「チームワーク」を大事にするとは?
A. チームが「プロジェクトに対して上手く進んでいるか」かを考える事
私の場合は、具体的には、以下のテクニックを利用しています。
- プロジェクトがうまく進んでいるかを客観視する
プロジェクトがうまく進んでいるかを客観視する
まずは、心理的安全性の確保などは考えず「プロジェクトがうまく進んでいるか?」を考えます。
理由は、うまく進んでいる場合はチームが上手く回っている事が多いからです。
チームが良くなってもプロジェクトが上手くいかなければ意味がありません。
プロジェクトを上手く進めるうえで結果的にチームが上手く連携がとれている状態を目指すのが良いと考えています。
私の場合は、以下を意識 / 実践しています。
マイルストーンが明確になっている事の確認
- 大枠のスケジュール(いつまでに / 誰が / 何を ) が明確になっている事
タスク管理 / タスクの優先度付けがちゃんと行われている事の確認
- 個々人の持ちタスクなどが把握できる状態になっている事
プロジェクトを進めるうえで出てくる課題をベースにチームメンバーと会話をする
- 会話をする事で個々人の詳細な状況を把握 / 対策を考える
- メンバーと会話を行う事で自分の頭の中の整理を行う
「一緒に」プロダクト開発を行うという意識を持つ
- チームメンバーが時間がかかっているタスクに対して積極的に介入する
知っておくと開発においてスムーズになる情報を分りやすくドキュメント化する
- アーキテクチャ や 実装指針
- デプロイ/リリース手順
- なぜ開発を行う必要があるのかの背景を説明したドキュメント
「アーキテクチャ」を大事にする
Q.「アーキテクチャ」を大事にするとは?
A. 開発者が「分りやすい設計 / 実装」を心がける 事
私の場合は、具体的には、以下のテクニックを利用しています。
- 1.データフローを統一化する
- 2.ビジネスルールをテストしやすいコードにする
- 3.レイヤを責務毎に分けて実装する
データフローを統一化する
Redux や Vuex などの「一方向アーキテクチャ」や
「伝統的なレイヤードアーキテクチャ」 がなぜ分りやすいかというと
「処理が行われる順番が決まっている」という点です。
「処理が行われる順番」が決まっていない場合は、循環参照などの
危険性も出てきます。
以下を実践すると良いのかなと思っています。
- ディレクトリ単位でレイヤ分けをする
- レイヤがどの順番で処理を行うかを決める
ビジネスルールをテストしやすいコードにする
ビジネスルールをテストしやすいコードにしておくとメリットが多くあります。
そのためにも、ビジネスルールのレイヤ(=Domain)をデータベース通信などのI/Oに依存しないようにすることが
大切になってきます。
なぜなら、データベースに存在する情報は、日々変化するものである為テストが常に同じ結果になるとは限らないからです。
「ダミーのデータをテストコードで扱えるよう」に「常に同じ結果」を返せるような設計にすると良いと思います。
データベース通信などの実処理に依存するのではなく、「データベース通信などの実処理を行った結果、
どういうDomainのデータが欲しいか?」を書いたインタフェースに依存するようにした方が良いと思っています。
ビジネスルールを単体テストしやすくすると、以下のようなメリットがあります。
- 以下が分かる事で開発速度・テスト速度が向上する
- テストコードで仕様が分かる
- テストコードがある事によって追加の修正 ...etc で、デグレが起きていない事を確認できる
レイヤを責務毎に分けて実装する
既に出ていますが、責務毎にディレクトリ(レイヤ)を分けてSOLIDな実装をすると良いと思います。 特に大事なのは、ビジネスルールを他のレイヤに依存させないプレーンな実装にすると良いかなと思います。
因みに弊社では、「オニオンアーキテクチャ」を採用している箇所があり、「ビジネスルール」/ 「外部とのI/O」/ 「プレゼンテーション」
にそれぞれ分かれています。
「ビジネスルール」が他の「外部とのI/O」や「プレゼンテーション」に依存していない為
以下のメリットを享受できています。
- テストコードが書きやすい
- 「同じビジネス文脈で利用されているビジネスのルール」の再利用がしやすい
最後に
この記事で「伝えしたいことを一つにしろ」と言われたら、 「手段と目的」を逆転させず「プロダクト開発」を成功させるように動く事が大事だという事を発信したいとおもっています。