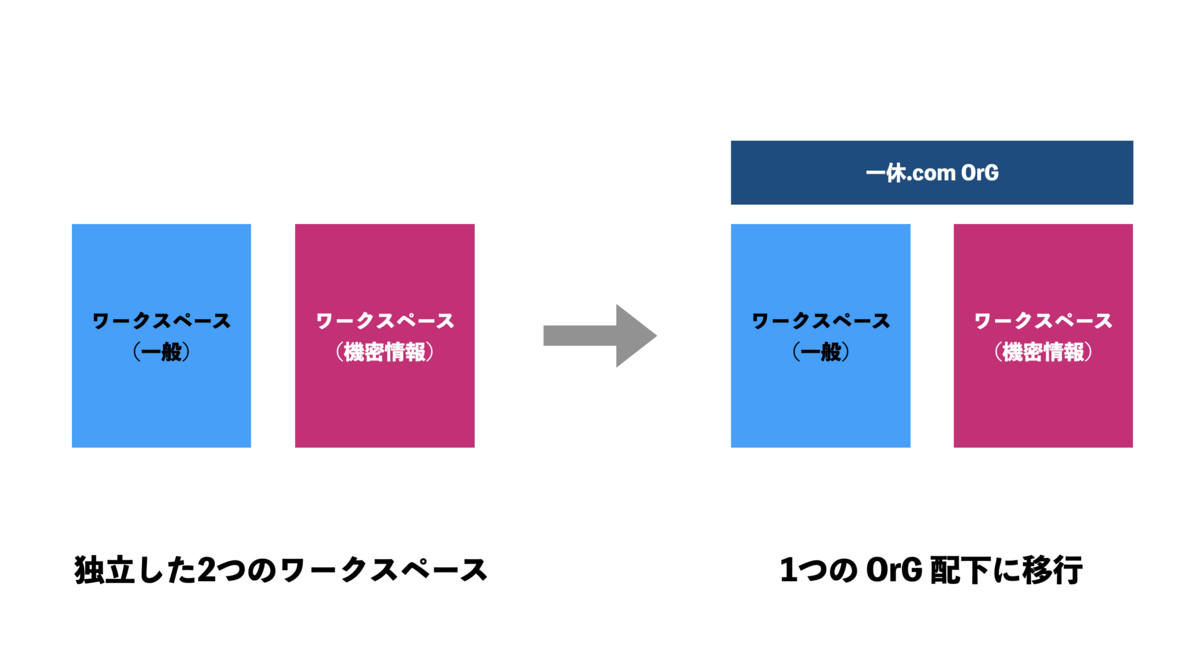
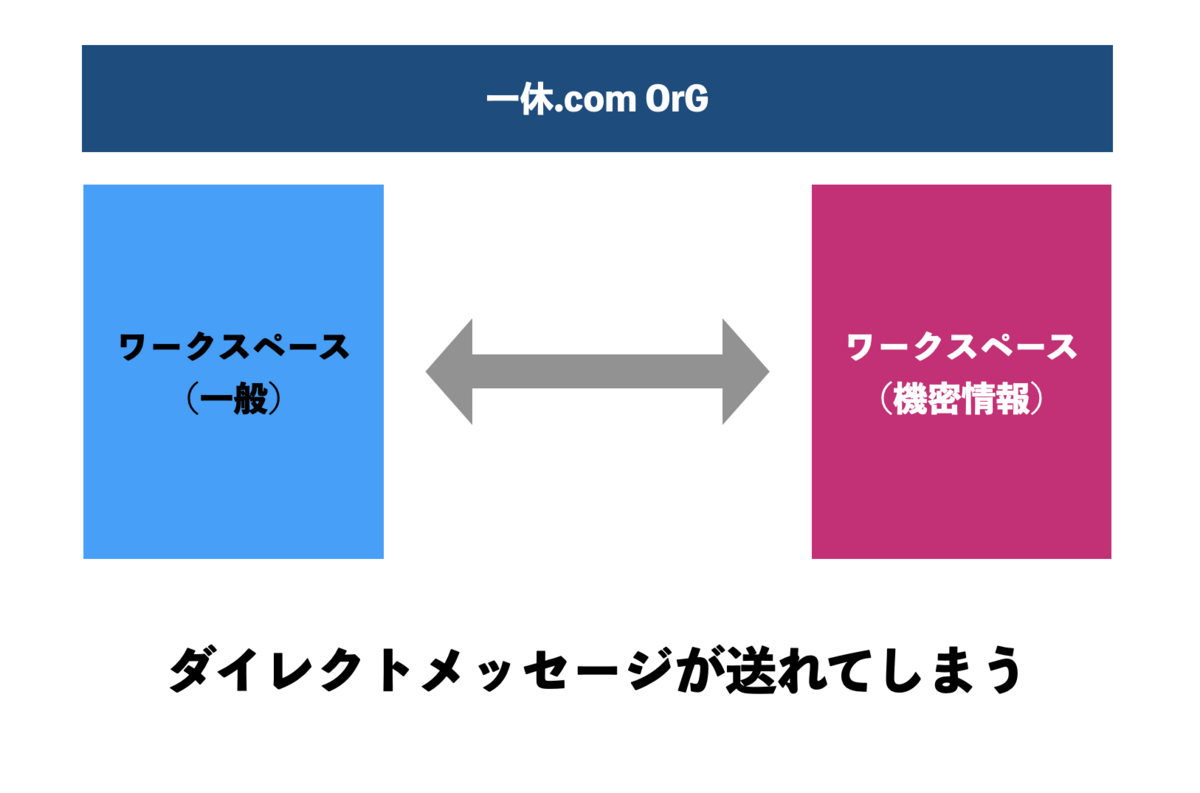
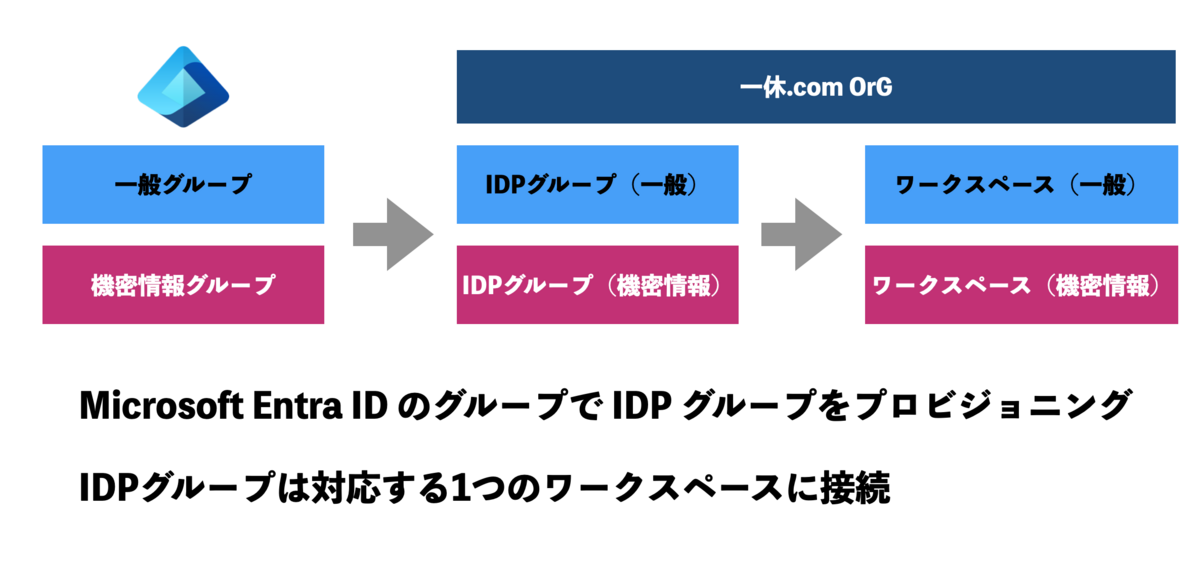
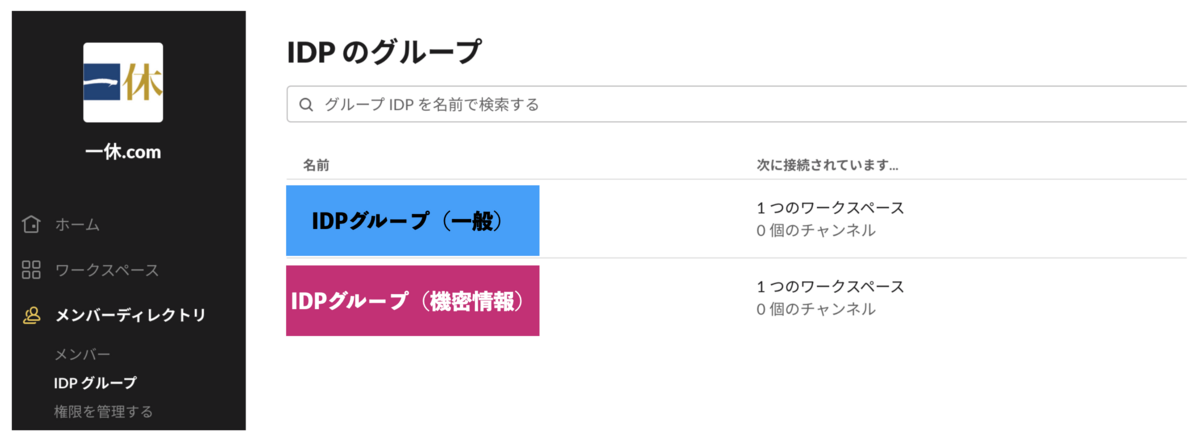
この記事は 一休.comのカレンダー | Advent Calendar 2023 - Qiita 10日目の記事です。
昨今は Web アプリケーション開発の世界でも、関数型プログラミングのエッセンスを取り入れるような機会が増えてきました。
とはいえ、一つのアプリケーションを 1 から 10 までがっちり関数型プログラミングで構成するというわけではなく、そのように書くこともあればそうでない従来からの手続き的スタイルで書くところもあるというのが現状で、どこまで関数型プログラミング的な手法を取り入れるかその塩梅もまちまちだと思います。まだ今はその過渡期という印象も受けます。
本稿ではこの辺りを少々考察してみたいと思います。
先日、Qiita Conference 2023 Autumn で以下のテーマで発表を行いました。
この発表では「関数型プログラミング最強!」という話をしたわけではなく、プログラムを関数型で考えるというのはこれこれこういうメンタルモデルにもとづいていて、一方で手続き型で考えるというのはこういうメンタルモデルにもとづく、という整理をしました。
より具体的には
- 関数型プログラミング ··· 式によって計算を宣言し、関数を適用することで値を得る
- 手続き型 (命令型) プログラミング ··· 文によって計算機に対し命令を行う。命令によって状態を更新することで結果を得る
と整理できるだろうという話をしました。
この発表の中で、蛇足的に以下のようなスライドを用意していました。
宣言的な記述はどちらかといえば純粋関数型的なパラダイムに基づくもの、命令的な記述は手続き的なパラダイムに基づくものと考えられる一方「純粋関数型言語」の Haskell はすべてのコードが宣言的になるかと思いきや、案外、手続き的な記述をすることもあるし、一度手続きを使うとそこから命令のコンテキスト以下は、手続き的なパラダイムに影響を受けることになります。
後に改めて触れますが、Haskell は「純粋関数型言語」としてのイメージが強いですが、上記のように、戻り値を戻さない (※ 実際にはユニット型を返してはいる) 手続き的なプログラミングが可能です。可能、というよりは、例えばミュータブルなデータ構造を更新したいときなどは、手続き的に書くのが自然です。
このように純粋関数型言語を使うにあたっても、関数型プログラミング / 手続き型プログラミングは一つのプログラムの中で混在する、混在していいものだということがわかります。
TypeScript でどこまで「関数型プログラミング」する?
Haskell の話に触れましたが、普段は私のチームのプロダクトは GraphQL バックエンドも含めて TypeScript でアプリケーション開発を行っています。
この TypeScript でのバックエンド開発については TypeScript による GraphQL バックエンド開発 - Speaker Deck のスライドでも詳しく解説していますが、やや関数型プログラミングよりのスタイルで開発を続けています。
以下のスライドで、その雰囲気が少し伝わるかと思います。
アプリケーションを記述するにあたり各種関数は、基本的に値を返す「式」として定義します。
計算は場合によっては失敗に分岐することがありますが、失敗は Result 型によって表現します。例外をスローすることはしません。そして Result 型を返す関数の合成 ··· 上のスライドの andThen などによって計算のパイプラインを作って実行します。
「Result」はその名前だけを見ると計算の結果だけに関与する部分的な型にも見えますが、実際には Result を導入すると計算構造の構築に Result のもつ合成を使うのが基本になり、実装スタイルに大きな影響を与えます。
例外を使わず合成によって一連の処理を構成するため、基本的にそのロジックの過程では大域脱出しません。結果、計算の流れが一方通行になります。また、Result によりおきうる失敗が全て明示されており、型によってそれを無視したプログラミングはできないようになっています。この両者の制約によってより堅牢な実装が可能になっています。
こう書くと、この宣言的プログラミングのスタイルや Result はとても良いもので何のトレードオフもないものに思えるかもしれません。しかし、やはりそんなことはありません。制約がかかる以上「いや、そこは手続き的に書いたら簡単なのに」と思うことはよくありますし、値が Result に包まれているおかげで、中身の値が欲しいのにいちいちコンテナを意識して実装をしなければならなかったり、面倒ごともあります。
こうなってくるとやはり「たとえどんな場合でも宣言的に、関数型ライクに書くのが良いのか?」という疑問がもたげてきます。
開発当時は、チームでもそういう話題になることもよくありました。手続き的なプログラミングは極力避けて、常に関数型プログラミング的に書くべきなのか? どうなんでしょう? という疑問です。
手続きを Result のコンテキストに閉じる ··· neverthrow の fromPromise / fromThrowable
ところで Result の実装には supermacro/neverthrow: Type-Safe Errors for JS & TypeScript というライブラリを使っています。
neverThrow には計算の合成に必要な基本的な関数が諸々定義されていますが、その中に一風変わった fromPromise や fromThrowable という関数があります。
その名の通り Promise (async / await も含む) や例外による大域脱出が使われている手続きを、Result のコンテナの中に閉じ込めるための関数です。これを使うことで、Result を返さないサードパーティのライブラリなども含めて、Result を使った自分たちの関数と合成することが可能になります。
視点を変えれば、この fromPromise や fromThrowable を使えば、Result を使いつつも、そのコンテキストの中では async / await を使ったり、例外を使ったりといった「作用のある手続き」を用いたプログラミングをすることができる... というわけです。
例えば以下は実際のプロダクションのコードの中にある、一部の実装です。
これは内部的なマイクロサービスへの HTTP リクエストのための関数ですが、相手側のサービスに無駄なリクエストを投げすぎないよう Redis にキャッシュさせながら問い合わせを行う、という実装になっています。Redist へのアクセスは keyv を使います。
非同期 IO で、かつ Redis を間に挟みながらオリジンの HTTP サーバーへのアクセスを行う実装です。昨今の Web アプリケーション開発ではよくある典型的な実装ですが、これを Result の合成で宣言的に書こうとすると Result が多段になりかなり面倒な実装になってしまいます。
そこで、手続きの流れは普段通り手続き的に async / await で書きつつ、その関数を前述の fromPromise によって Result のコンテキストに包みます。これで「手続き的に書いた方が良い場面ではそうする」ことができます。
const restoreAccessToken =
({ keyv, key, requestFunc }: { keyv: Keyv; key: string; requestFunc: requestAccessToken }) =>
(requestArgs: requestAccessTokenArgs): ReturnType<requestAccessToken> => {
const promise = async () => {
// キャッシュを検索
const value = await keyv.get(key)
if (value)
return {
access_token: value as string,
expires_in: 0,
token_type: 'Bearer' as const,
}
// キャッシュになかったらリクエストする
return requestFunc(requestArgs).match(
(response) => {
// キャッシュに格納
keyv.set(
key,
response.access_token,
(response.expires_in - 600) * 1000
)
return response
},
(error) => {
throw error
}
)
}
// fromPromise で Result に包む。エラーの型が unknown になってしまうのに注意
return fromPromise(promise(), (error: unknown) =>
error instanceof AuthenticationError ||
error instanceof ValidationError ||
error instanceof NetworkError
? error
: new NetworkError(error as string)
)
}
このように全てを Result を使って関数型/宣言的に··· とするのではなく、非同期 IO が絡み合う箇所など、手続的に書く方がシンプルに書けるということもよくあるわけです。
関数型プログラミングに固執せず、手続き的に書けばいい時はそうすればいい、ということになります。じゃあその「手続き的に書けばいいとき」というのは一体どういう時なんでしょうか? こういうときはなかなか、TypeScript だけをやっていてもよくわかりません。
そこで他の言語、手続きも書ける純粋関数型言語 Haskell ではどのような考えに基づいてみんな実装しているのか、その例を少し見てみることで相対化してみましょう。ただし当然この短い記事で全部を見ることはできません。いくつかの典型例に着目して見ていくことにしましょう。
Haskell でも手続き型で記述するケース
先述の通り Haskell は「純粋関数型」言語ですが、純粋関数型即ち関数型でしか書けないわけではなく実際には手続き型で記述することもよくあります。むしろ積極的に手続きを使う場面もあります。
なお、手続きHaskellについては、以下の書籍がおすすめです。30ページほどの薄い本なので、さっと読めます。
booth.pm
IO を行いたいとき
IO というのは外界の世界とのやり取りを、計算機に命令する手続きだと考えられます。「計算機に命令する」のですから、自然と手続き型 (命令型) のコードを書くことになります。
main :: IO ()
main = do
name <- getLine
putStrLn ("Hello, " ++ name)
見ての通り putStrLn からは戻り値を受け取っていません。つまり「文」に相当する記述になっています。
厳密には putStrLn は文ではなく IO () 型の値を返す式です。他の返値を受け取らない式も同様なのですが、ここでは説明のため手続き型プログラミングでいうところの文相当だと思ってください。
ところで main の後ろに do という記述があります。何気ない記述ですが、これこそが Haskell の手続きプログラミングを可能にするものです。
上記を do 記法を使わずに記述することもできるわけですが、
main = getLine >>= (\name -> return ("Hello, " ++ name)) >>= putStrLn
その場合 Monad 型のバインド演算子 >>= を使って関数合成で記述することになります。getLine 関数によって端末からの入力値を受け取ることができますが、それは外界からやってきた値であり、IO 型のコンテナに入っています。それを扱うため、上記のような少し変わった記述が必要になります。
do 記法はこのイディオムを逐次で記述できるようにするシンタックスシュガーです。つまり上記のバインド演算子による実装は、do を脱糖した場合の記述です。
do 記法があることで、コンテナの中に入った値を扱いやすくなります。結果、作用を起こしてその結果を受け取ったりする記述が容易になります。計算機に命令して作用を起こし、その結果を得る··· 手続き的プログラミングそのものですね。
do 記法を使わずに記述していけば見た目は関数の合成になるわけですが、そうした方がいい理由は特にありません。たとえば複数の値を一つずつ出力していきたいのであれば mapM や traverse などを無理して使わなくても、素直に for_ で手続き的にループを回して出力すれば良いのです。
import Data.Foldable (for_)
main :: IO ()
main = do
for_ [1 .. 10] $ \i -> do
print i
ミュータブル配列を使いたいとき
Haskell のデータ構造は基本、イミュータブルです。
しかし場合によってはイミュータブルなデータ構造だけでは効率的な実装が不可能な場合があります。
その典型例といえば、配列です。先日 Haskell の Array という記事でも投稿しましたが、Haskell にはイミュータブルな配列と、ミュータブルな配列があります。両者を都度変換して使うこともできます。
イミュータブルな配列は以下のように使います。
{-# LANGUAGE TypeApplications #-}
import Data.Array.IArray
import Data.Array.Unboxed (UArray)
main :: IO ()
main = do
let as = listArray @UArray (0, 5) [3, 1, 4, 1, 9, 2 :: Int]
print $ as ! 2
! 演算子が配列への添字アクセスを行う関数で、もちろん O(1) です。
問題は配列の更新です。
イミュータブルなデータ構造は直接は書き換えられないので、更新時にはコピーが発生します。
main :: IO ()
main = do
let as = listArray @UArray (0, 5) [3, 1, 4, 1, 9, 2 :: Int]
as' = as // [(0, 4), (1, 8)]
print $ elems as'
このとき配列全体がコピーされるので、更新関数 // の計算量は O(n) になります。
単一の特定の要素を更新する場合は O(1) で済んで欲しいわけですが、イミュータブルな配列ではそれは不可能です。O(1) での更新が必要なときはミュータブルな配列を使うと良いでしょう。
import Data.Array.IO (IOUArray)
import Data.Array.MArray
main :: IO ()
main = do
as <- newListArray @IOUArray (0, 5) [3, 1, 4, 1, 9, 2 :: Int]
writeArray as 0 4
writeArray as 1 8
print =<< getElems as
このようにミュータブルな配列を書き換えるのには writeArray などの関数を使います。この関数は「値を更新しろ」という命令を行うものですから、戻り値はありません。すなわち文 (相当) になります。
上記のミュータブル版の実装を見ると、writeArray の戻り値を受け取っていないだけでなく、イミュータブル版の実装の時には出てこなかった <- や =<< などの演算子が必要になっています。詳細は割愛しますが、これらはやはり「データ構造を直接書き換える」という作用の結果必要になるもので、IO やミュータブルなデータの更新などの作用を起こすと周囲にも影響が及ぶことが見て取れます。
同様の例として、先の発表スライドの以下のページを見てください。Union-Find (Disjoint Set とも呼ばれます) というデータ構造とそのアルゴリズムを実装した時の比較です。
Union-Find は内部的に集合の管理をするわけですが、その管理用のデータ構造にイミュータブルなデータ構造を使った場合と、ミュータブルなデータ構造を使った場合のインタフェースの比較を行なっています。
左の、Union-Find がイミュータブルになケースでは、Union-Find 内の実装はもちろん、Union-Find を利用する側の実装もイミュータブルにそれを使うことになるので式で宣言します。より宣言的に、関数型プログラミング的にプログラムを構成することになります。
一方、右側のミュータブルな Union-Find はどうでしょうか。
左の実装とは異なり、forM_ (先の for_ と同じです) や unless など戻り値を伴わない制御構造文的なものを使った実装になります。これは無理にそうしているわけではなくて、ミュータブルなデータ構造を更新するのには文を使うことになり、その結果、制御構造も値を戻さない文を使うことになるだけです。作用によってデータを更新する、ミュータブルなデータ構造を使うとそれを皮切りに、そのコンテキストの実装は自然と手続き型になることを意味します。
ということはそのままプログラム全体を構成していくと、プログラム全体が手続き的になってしまいます。そこでミュータブルなデータ構造を改めてイミュータブルなデータ構造に変換するなどして、作用への依存を切って、関数型での記述に戻していくこともできます。
なお、Union-Find はそのデータ構造の都合上、ミュータブルなデータ構造を使って構成する方が望ましいと考えています。具体的にはクエリ時に経路圧縮をすることによってデータ構造内部のバランシングを行うわけですが、このバランシングに作用を伴うためです。詳しくは以前 Haskell で Union-Find とクラスカルのアルゴリズム に記述しました。
手続き的に書く方が「わかりやすい」ケース
IO や ミュータブルなデータ構造の例は、作用があるゆえ結果的に自然と手続き的に書くに至るというようなケースでした。
積極的に手続き的プログラミングを選択したというよりは、半ば受動的に、手続き的に記述するようなケースです。
では、その積極的に手続き的プログラミングを選択したいケースも見てみましょう。
以下 AtCoder の競技プログラミングの問題を題材にしますが、問題の内容は重要でありませんので詳細を理解する必要はありません。問題を解くためのコードの形がどんなものになるかにだけ着目していってください。
次の再帰による深さ優先探索 (DFS) の問題を解いてみます。
atcoder.jp
グラフが与えられる、頂点 1 を出発点にして探索を行った時、同じ頂点を複数通らないパスを数え上げていったときその個数 K を出力する。ただし K が 106 より大きくなる場合はそこで数え上げをやめる。という問題です。DFS を行えばいいだけの問題に見えますが、経路を数え上げた結果上界に達したら計算を打ち切る... いわゆる枝刈りが必要です。
この手の再帰を回しながら数え上げをする実装は、手続き型で書くと思いのほか簡単です。
以下は Python による実装です (ChatGPT に書かせました)
数え上げは再帰関数のスコープを跨いで行う必要がありますが、カウンタ値 k を global で関数のスコープ外で生存できるようにし、上界の 106 に達したら早期 return で大域脱出すれば良いだけでです。
import sys
sys.setrecursionlimit(10**7)
n, m = map(int, input().split())
g = [[] for _ in range(n)]
for _ in range(m):
u, v = map(int, input().split())
g[u - 1].append(v - 1)
g[v - 1].append(u - 1)
visited = [-1] * n
k = 0
def dfs(v):
global k
k += 1
if k > 10**6:
k = 10**6
return
visited[v] = 1
for u in g[v]:
if visited[u] == -1:
dfs(u)
visited[v] = -1
dfs(0)
print(k)
同じような実装を Haskell で、純粋関数で書こうとするとグローバル変数や大域脱出に相当するところをどうするか悩むことになります。
以下は最初に書いた、純粋関数で実装した実装です。
dfs nextStates visited v = do
let visited' = IS.insert v visited
us = filter (`IS.notMember` visited') (nextStates v)
foldl'
( \k u ->
if k >= 10 ^ 6
then k
else k + dfs nextStates visited' u
)
(length us)
us
main :: IO ()
main = do
[n, m] <- getInts
uvs <- replicateM m getTuple
let g = graph2 (1, n) uvs
k = dfs (g !) IS.empty (1 :: Int)
print $ min (10 ^ 6) (k + 1)
foldl' で畳み込みをする際に上界を超えていたらそれ以上は再帰を行わない、ということを途中で行なっています。
再帰をまたいだカウンターのものを用意するのではなく foldl' の計算結果のアキュムレータを再帰関数が返したものを受け取って、さらにそれをまた foldl' の初期値にして... ということを繰り返しており、その動きを頭の中で想像しようとするとなかなか大変···認知負荷で頭がパンクしそうになります。
Python の実装に比べると、ずっと難しく感じますね。なお、誤解がないよう説明すると、ここではコードの読みやすさが簡単・難しいという話をしているわけはなくて、計算の構造、計算を実際に頭の中で追うときの認知負荷の観点で簡単か、難しいかを論じています。
もとい、先の Python の実装のように再帰関数のコンテキスト中にカウンタ値を共有して計算を打ち切るような実装はできないのものでしょうか?
そこで手続き型プログラミングです。
State モナドを使うと、関数の実行コンテキスト間で値を共有しながら計算を進めることができます。実質的に、関数の実行コンテキスト内部に閉じたグローバル変数のように使えます。
dfs nextStates visited v = do
let us = filter (`IS.notMember` visited) (nextStates v)
modify' (+ length us)
k <- get
when (k < 10 ^ 6) $ do
forM_ us $ \u -> do
dfs nextStates (IS.insert v visited) u
main :: IO ()
main = do
[n, m] <- getInts
uvs <- replicateM m getTuple
let g = graph2 (1, n) uvs
k = execState (dfs (g !) IS.empty 1) 0
print $ min k (10 ^ 6)
State モナドの更新には、例によって戻り値のない命令 modify' などを使います。カウンタ値が上界を超えたら再帰を呼ぶ必要はないし、純粋関数でやっていた時のように値を戻す必要もないので戻り値のない when により分岐を制御します。
dfs 関数の中が、手続き的になりました。こちらの方が計算の流れは簡単に追うことができるでしょう。
この問題は比較的シンプルではあるので、純粋関数で構成してもなんとかなるかなとは思います。
一方、再帰を呼ぶ、呼ばないの分岐がより複雑になってくると再帰から戻ってきた値をどう結合するかも含めて考えるときの認知負荷が大きくなり、きつくなってきます。
再帰関数による全探索の、別の問題を見てみます。
atcoder.jp
この問題は、縦長の畳、正方形の畳がある決まった数が与えられたとき、それを部屋の中にちょうどよく敷き詰められるか? というパズルを再帰的に全探索することで解く問題です。
詳細は割愛しますが、こちらの問題も State モナドを使って手続き的に記述することで、先のグラフ問題同様に、再帰を継続するしないの選択や、数え上げを、戻り値を戻すことを意識せずに実装できるので比較的、頭の中にあるモデル通りの実装が可能です。
これを純粋関数でやろうとすると再帰から戻ってきた値をどう扱うか、書けないわけではないですが、少し面倒になるでしょう。
dfs (h, w) _ _ s [] = do
modify' (+ 1)
dfs hw a b s (v@(i, j) : vs)
| Set.member v s = dfs hw a b s vs
| otherwise = do
when (a > 0) $ do
let !yoko = (i, j + 1)
!tate = (i + 1, j)
when (inRange ((1, 1), hw) yoko) $ do
dfs hw (a - 1) b (Set.insert yoko $ Set.insert v s) vs
when (inRange ((1, 1), hw) tate) $ do
dfs hw (a - 1) b (Set.insert tate $ Set.insert v s) vs
when (b > 0) $ do
dfs hw a (b - 1) (Set.insert v s) vs
main :: IO ()
main = do
[h, w, a, b] <- getInts
let vs = range ((1, 1), (h, w))
k = execState (dfs (h, w) a b Set.empty vs) (0 :: Int)
print k
IO を扱いたいとき、ミュータブルなデータ構造を扱いたいとき、再帰関数の例のように手続き的に書く方がわかりやすいとき、など Haskell での手続きプログラミングの例を見ました。いずれの例も、無理をして手続き的に書いているわけではありません。関数型言語を使うからと言って、式による計算の宣言、つまりは関数型プログラミングに固執する必要はないことがわかります。
do 記法や State モナドは決して特別なものではなく言語の基本機能として用意されているものです。つまり、その場その場に応じて適切なパラダイムを選択する ... 関数型と命令型のマルチパラダイムでコードを実装しても特に問題ないからこそでしょう。
ただし手続き型の命令に伴って副作用が現れる場合に、Haskell は型やモナドによって明示的にそれを扱っています。そのため比較的安全に、手続き型プログラミングを純粋関数型プログラミングの中に混在させることが可能になっている... というところが大きなポイントです。これによって都度パラダイムを行き来してもプログラム全体を破壊することなく、堅牢な記述を続けることができるというわけです。
まとめ
Haskell の手続きプログラミングの例を見ました。Haskell でも手続き的プログラミングをする場面というのは案外多くあることがわかります。そしてその、関数型プログラミングと手続き型プログラミングのパラダイムの行き来をスムーズにするのに、do 記法や型が重要な役割を果たしています。
手続き型プログラミングの副作用を安全に隔離しながらも記述のオーバーヘッドを抑えるのに do 記法が貢献しているとも言えます。
裏返せば、do 記法のような文法の支援のないプログラミング言語で無理に純粋関数型だけでやっていこうとすると「ここは手続き的に書けばいいのに」という場面で柔軟な方針が取れず、自分で自分の足を撃っているような状況に陥るかもしれません。例えば Result はモナドのようなものですが、Result が入れ子になって多段になると、すぐにコードが複雑化します。(Rust など、最近のプログラミング言語には Result が組み込みで用意されているものもありますが、そこにはプログラミング言語による文法の支援が、セットで付いています。)
TypeScript には関数型プログラミング言語的な側面があるとはいえ、一方で Haskell の do 記法 (やモナド) のようなプログラミング言語組み込みの機構はありません。よって、純粋関数型言語と完全に真似たスタイルでやっていこうとすると、少し困難が伴うかもしれません。
ここまでで分かったことを列挙すると以下のような考察になります。
- 明示的に作用を起こしたいのであれば手続きを使えば良い。ただし Haskell はその結果の作用から、純粋関数の世界を守ってくれる機構がある。それがない言語では、作用が伴う時その影響をどう管理するかが論点になる
- TypeScript には do 記法がない。(パターンマッチや代数的データ型も、エミュレートはできるものの十分とはいえない )。そして TypeScript で記述するようなアプリケーションは非同期 IO をたくさん行うものが多い。···にもかかわらず完全関数型スタイルでやっていくというのには道具が足りてない (と思います)
- TypeScript でも無理なく宣言的に書けるところはそうすれば良いだろう。同様に、手続き的に書く方がいい場面では (もしその手続きに副作用を伴うなら、それを手続きのスコープに留めることを何かしらで担保しつつ) 手続きで書くので良さそう。「関数型プログラミング」に固執する必要は (Haskell ですらそうなのだから、道具の足りてない TypeScript ではなおのこと) ない。
- 純粋な値だけで構成されるようなロジックの場合は、イミュータブルかつ宣言的に書いていってもなんら不便はない
- 副作用のあるところと、純粋に書けるところを分離することでその併用が可能になる。その点で、高階関数による Dependency Injection を積極的に使って業務ロジックの IO への依存を切っていくのは良いプラクティスと言える
- neverthrow には各種合成関数、 fromPromise や fromThrowable などで、コンテナに入っている値を扱いやすくする機構はあるものの、やはり十分とはいえず。 プログラミング言語そのものがそれをサポートしている言語などに比較するとやはり不便はある。(私たちはシステムが扱っている業務の都合上、その不便を受け入れてでも堅牢性の方を優先しました)
後日さらに理解が深めた結果、私自身がこの考察を否定することもあるかもしれませんので、その点はご了承ください。
長々とした文書をここまで読んでいただき、ありがとうございました。