このエントリーは 一休.comのカレンダー | Advent Calendar 2023 - Qiita の22日目の記事です。
レストランプロダクトUI開発チームの鍛治です。
一休レストランのフロントエンドを担当しています。
一休レストランでは Next.js App Router Remix を採用しています。
user-first.ikyu.co.jp
昨年の終わり頃から始まった一休レストランのリニューアルですが、フロントエンドは Nuxt v2 (Vue 2) から Next.js App Router (React) に、という大きな切り替えで、不慣れだった我々は React 初心者がひっかかる落とし穴を全部踏み抜いてきました。
例えば、チュートリアルに従って useState で変化する状態を定義して、最初はそれで全てがうまくいっていました。機能追加していく過程でいつの間にか一つ増え二つ増え、あとはズルズルと。
ふと我に返ると一つのコンポーネントに10個もの useState が生えてしまっていました。
その結果、 &&, ||, ?? のオンパレードと三項演算子だらけの JSX だけが残りました。何度も何度も読み返してるのに、コンポーネントが今どんな状態にあるのか、さっぱり把握できない…
他にも、
バケツリレー コールバック
useEffect 問題
といった落とし穴を踏み抜いてきました。
フロントエンドの状態管理って本当に難しいですよね。
あらためて本日は React 状態管理改善の第一弾として useState 濫用からどう抜け出したのかについてお話しします。
コールバックや useEffect 問題は来月以降の記事でご紹介する予定です。
useState の難しさ
まずは一番初歩的なところから考えてみましょう。
複数のuseStateフックを使用する場合、予期しない状態の組み合わせが発生する可能性があります。
function Sample() {
const [ show, setShow] = useState( false );
const [ disabled, setDisabled] = useState( false );
const toggle = useCallback(() => {
setShow(( prev) => ! prev);
} , [] );
const toggleDisabled = useCallback(() => {
setDisabled(( prev) => ! prev);
} , [] );
return (
<>
< button onClick = { toggle} disabled= { disabled} >
show
< /button>
< button onClick = { toggleDisabled} > disable< /button>
< SampleModal show= { show} />
< />
);
}
このシンプルな例では、show(モーダル表示用)と disabled(ボタン無効化用)の二つの状態を管理しています。
しかし、たった二つしかないのに show === true && disabled === true のように、ボタンが無効化されているにも関わらずモーダルが表示されている、という矛盾した状態を表現できてしまいます。useState で管理する状態が増えれば増えるほど、矛盾した状態を生んでしまう可能性は高くなります。
この問題を解決するためには、コンポーネントの粒度を小さくし、useState には primitive 値を入れず構造化されたデータを用いて、ありえない状態を生まないようにするのが自然な発想でしょう。
type State = Initial | Disabled | Modal
type Initial = {
type : 'Initial'
disabled: false
show: boolean
}
type Disabled = {
type : 'Disabled'
disabled: true
show: false
}
type Modal = {
type : 'Modal'
disabled: false
show: true
modalData: ModalData
}
function Sample() {
const [ state, setState] = useState< State>( { type : 'Initial' , disabled: false , show: false } )
const open = useCallback(() => {
setState( { type : 'Modal' , modalData: 'data' , disabled: false , show: true } )
} , [ setState] )
const toggleDisabled = useCallback(() => {
if( state.disabled) {
setState( { type : 'Disabled' , disabled: true , show: false } )
} else {
setState( { type : 'Initial' , disabled: false , show: false } )
}
} , [ setState] )
return (
<>
< button onClick = { open} disabled= { state.disabled} >
show
< /button>
< button onClick = { toggleDisabled} > disable< /button>
< SampleModal show= { state.show} />
< />
)
useState + union 型では足りなかった
上述した実装のように、union 型によって不正な状態が作られなくなりました。
遷移はイベントハンドラ内で暗黙的に記述されます。上記のモーダルでは状態が2つしかなく、シンプルな実装なので遷移の全体像を把握できていますが、状態の数が増え遷移が複雑になると遷移の全体を把握するのが困難になり、人為的に遷移先を決定するロジックをテストする必要があります。結果、誤って不正な遷移が紛れ込む場合があります。
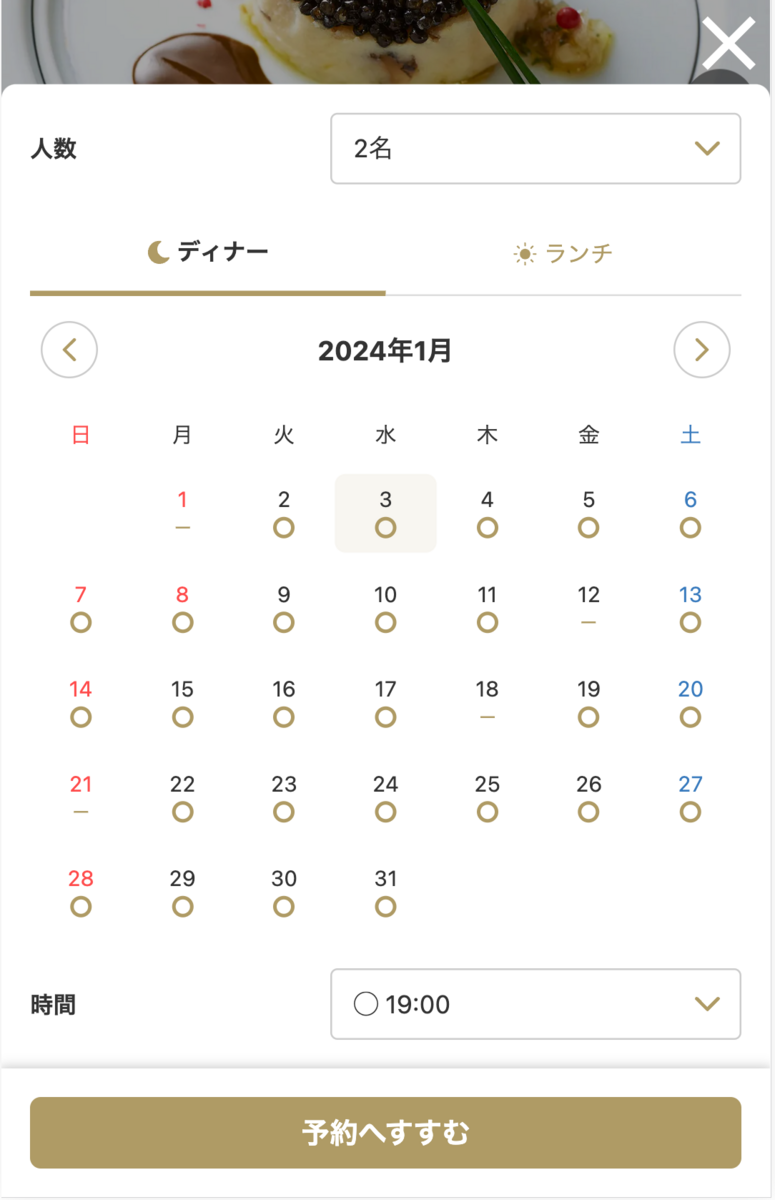
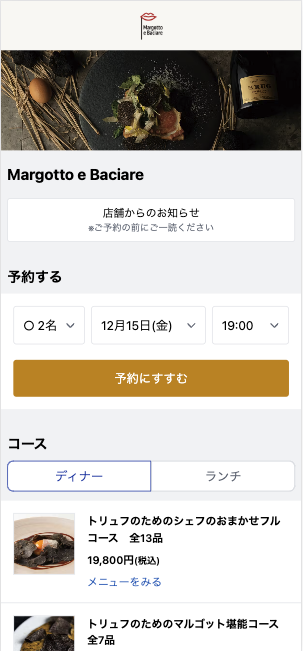
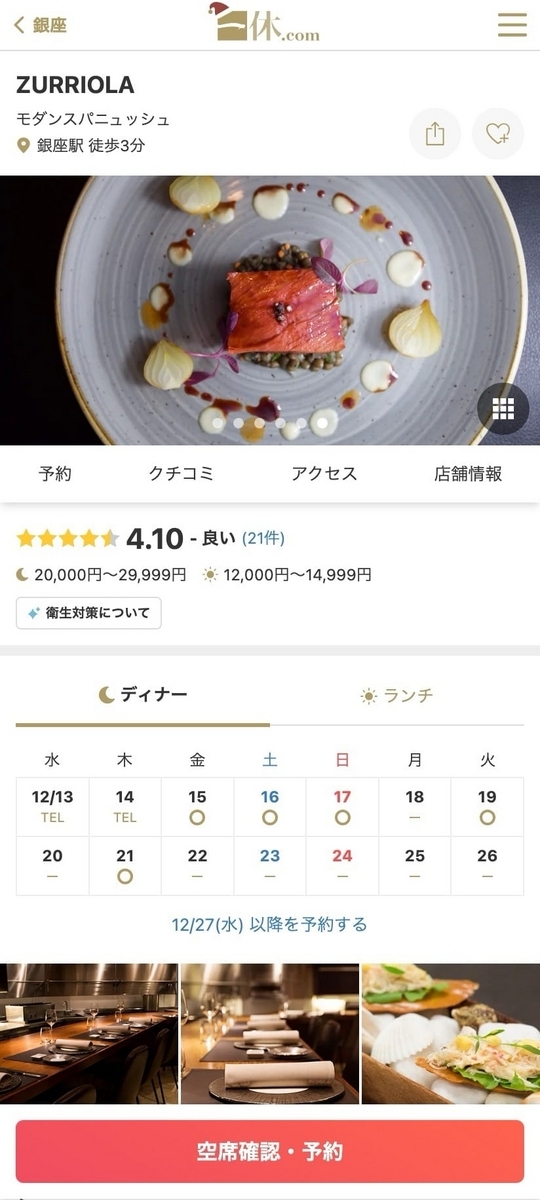
例えば、一休レストランでは空席確認カレンダーという機能があります。
空席確認カレンダー
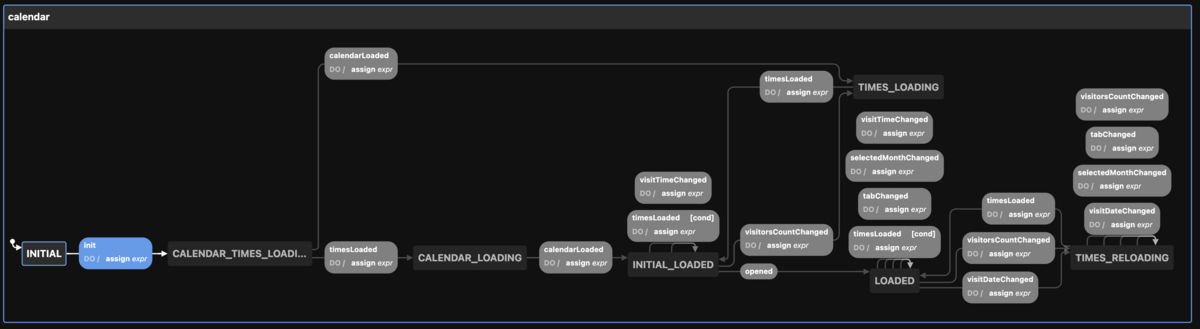
上記空席確認カレンダーの状態遷移図は以下のようになります。黒色で囲われているのが状態で、灰色で囲われているのが遷移イベントです。
カレンダーの状態遷移図
状態が7個、遷移イベントが20個あり、イベントハンドラ内での遷移先を決めるロジックが複雑になってしまい不正な遷移を起こしてしまう可能性がありました。
このような不正な遷移を人為的ではなく機械的に防ぐために、state machine を導入します。
state machine とは?
state machine は複数の「状態」と「状態間の遷移」で構成されます。
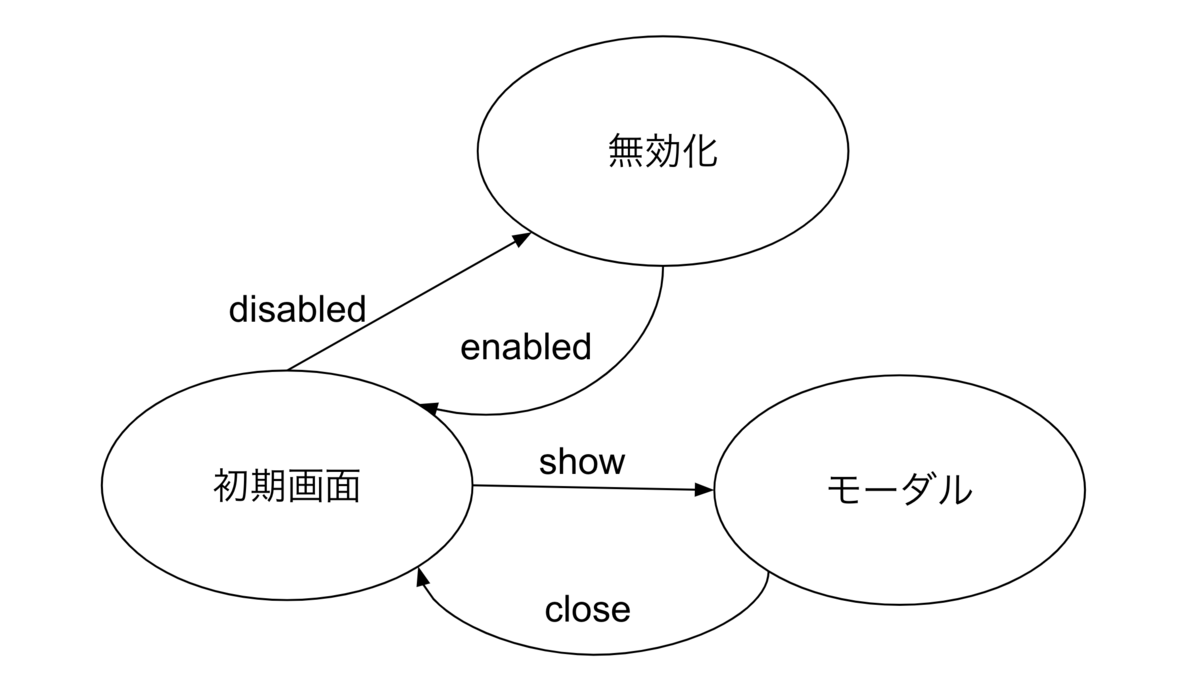
上述した web 画面のシナリオを例にすると「フラットな状態」(通常の状態)から「モーダルが開いた状態」への遷移は「 show ボタンをクリックする」というイベントによって行われます。
「モーダルが開いた状態」では再度 「show クリック」イベントが発生しても、そのイベントに対応する状態遷移は定義されていないので、それ以上何も起きません。
また「フラットな状態」から最初に disabled ボタンが押されて (disable イベントが発火して)「ボタンが無効化された状態」になると、そこで仮に show イベントが発火しても、同様に show イベントに対応する状態遷移が定義されていないので、「ボタンが無効なのにモーダルが開いてしまう」という矛盾した状態が生じません。
モーダルの状態遷移図
state machine では、あらかじめ定義した状態とその状態間の遷移しか存在しないので、予期しない状態に陥ることがありません。state machine を導入すると、アプリケーションロジックを明確かつ宣言的に定義できるのが非常に魅力的なポイントです。
XState (state machine) の導入
state mcahine を導入するために、XState を使った状態管理方法を導入することを決定しました。
もちろん他の解決策もあったと思います。
例えば、弊社 CTO が以前ご紹介した TypeScript の discriminated union (タグ付きユニオン型)で状態を、関数で遷移を表現する手法はその一つであり、弊社プロダクトで実績あるソリューションであることは間違いありません。
techplay.jp
ただ、現在の自分達では、制約のない状況下でうまく型を定義して、状態を完全にコントロールできるという自信は持てませんでした。state machine もどきの不完全な物を生み出してしまわないか不安があったのです。
XState であれば state machine を正しく定義することを強制されます。技術としてのフレームワークに留まらず、思考のフレームワークとしてガイドレールを提示してくれる点を評価しました。
XState とは?
stately.ai
state machineを作成することができる非常に高機能なライブラリです。
例えば、フロントエンドのサンプルとしてよく用いられる TODO リストを XState で実装*1 すると以下のようになります。
type TodoList = {
items: {
id: number
name: string
completed: boolean
}[]
}
type TodoEvent = Add | Toggle | Disable | Enable
type Add = {
type : 'ADD'
item: {
id: number
name: string
completed: boolean
}
}
type Toggle = {
type : 'TOGGLE'
id: number
}
type Disable = {
type : 'DISABLE'
}
type Enable = {
type : 'ENABLE'
}
type TodoState = { value: 'ACTIVE' ; context: TodoList } | { value: 'INACTIVE' ; context: TodoList }
export const machine = createMachine< TodoList, TodoEvent, TodoState>( {
initial: 'ACTIVE' ,
states: {
ACTIVE: {
on: {
ADD: {
target: 'ACTIVE' ,
actions: assign(( ctx, event) => ( { items: [ ...ctx.items, event.item] } )),
} ,
TOGGLE: {
target: 'ACTIVE' ,
actions: assign(( ctx, event) => ( {
items: ctx.items.map(( item) =>
item.id === event.id ? { ...item, completed: ! item.completed } : item
),
} )),
} ,
DISABLE: 'INACTIVE' ,
} ,
} ,
INACTIVE: {
on: {
ENABLE: 'ACTIVE' ,
} ,
} ,
} ,
} )
まず state として TODO を追加したりトグルを変更が可能な状態の ACTIVE と、なにもできない状態の INACTIVE を定義します。
次に、各 state が各イベントを受け取った時にどの状態に遷移するか、すなわち状態遷移を on で定義し、その状態遷移時の副作用としてのデータ更新を actions で指定することで、state machine が完成します。
XStateでは、内部情報として context (詳しいことは後のセクションで説明します)を持ちます。ADD イベントでは context である items に 新しい TODO を追加しています。
XState で定義した state mahine では、INACTIVE の状態で ADD や TOGGLE のイベントに対する状態遷移を定義していないので、ありえない状態に遷移しないことが保証されます。 。
context
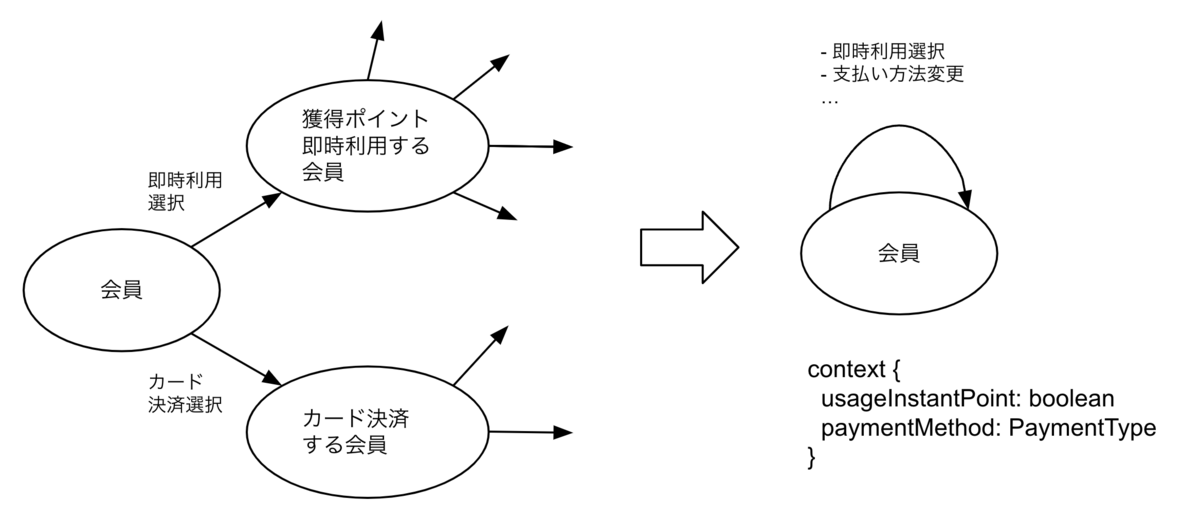
context とは、state machine が扱う状態の「詳細」や「変動する部分」を吸収して、複雑な状況に対応する仕組みです。
state machine 、厳密には有限状態機械(FSM: Finite State Machine)の「有限」は、あくまで数学的な「有限」です。
実際のアプリケーションでは、管理しなければならない状態に紐づくデータや条件が複雑で、有限状態機械を原理的に適用すると、たとえ「有限」であっても、人間の認知能力ではとうてい把握しきれない膨大なバリエーションを生み出してしまいます。
有限状態機械を現実的に利用するために 状態とその状態に関連するデータを分離して、context という形で保存・管理します。
例えば以下のように、ユーザーの入力やアプリケーションの現在の状態など、状態自体ではなく、状態の「内容」を表すデータのことです。
予約する人数日時
予約の際に選択する支払い方法
使用するクーポン情報
予約入力の状態遷移図
XState で管理すべきでない状態
XState で全ての状態を管理すべきと言ってるわけではありません。ボタンを押すとモーダルが表示される状態遷移は、XState で管理してしまうと却ってオーバーエンジニアリングになってしまいます。
また、以下の場合は状態として持つべきではありません。
状態遷移から独立しており、値が操作の過程で変化しないもの
例えば、API レスポンスは state machine の遷移に変化する値ではないので XState で管理すべきではなく、useState で管理すべきです。
XStateで管理すべき基準としては
1つのコンポーネントで useState が3つ以上定義されている
何かアクションを起こした時の遷移先が2つ以上ある
場合だと思ってます。(プロダクトによって基準は違うと思うのであくまで目安です)
XStateを導入して良かったこと
フロントエンドの改修が容易になった
state machine によりありえない状態ができないことが担保されているので、フロントエンドの改修をする際に大きいバグが起きなくなりました。
実装前の仕様 / モデリングの議論ができるようになった
state machine が画面のドメインモデルとなるので、画面や機能を作成する際にどのような state machine にするか議論することで、意図せずも画面や機能のモデリングの議論ができるようになりました。
所感
XState による state machine という考え方のガイドレールができたことで、条件文を最小限にする state mahine のメンタルモデルが形成されてきたように思います。
また、上述したように全て XState で管理すべきだとは思ってません。適材適所で XState をうまく活用していきたいです。
さいごに
一休では、より良いサービスを作ってくれる仲間を募集しています!
www.ikyu.co.jp
カジュアル面談も実施していますので、ぜひお気軽にご連絡ください!
hrmos.co